Convolution Neural Network
All images are classified to the same size
Simplification
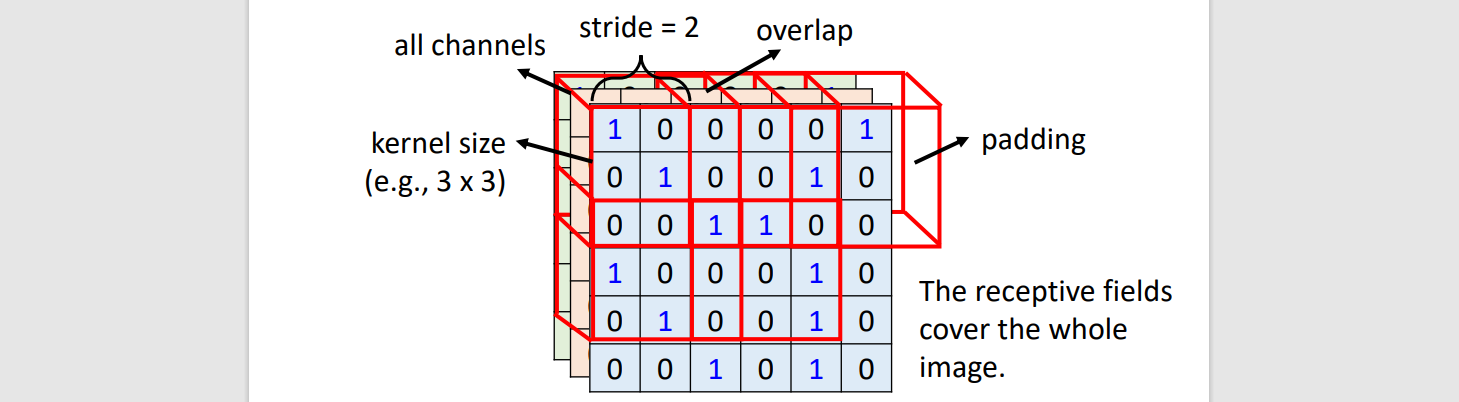
Receptive field
- Kernel size = 3
- Stride = 2
- Padding: compensate 0
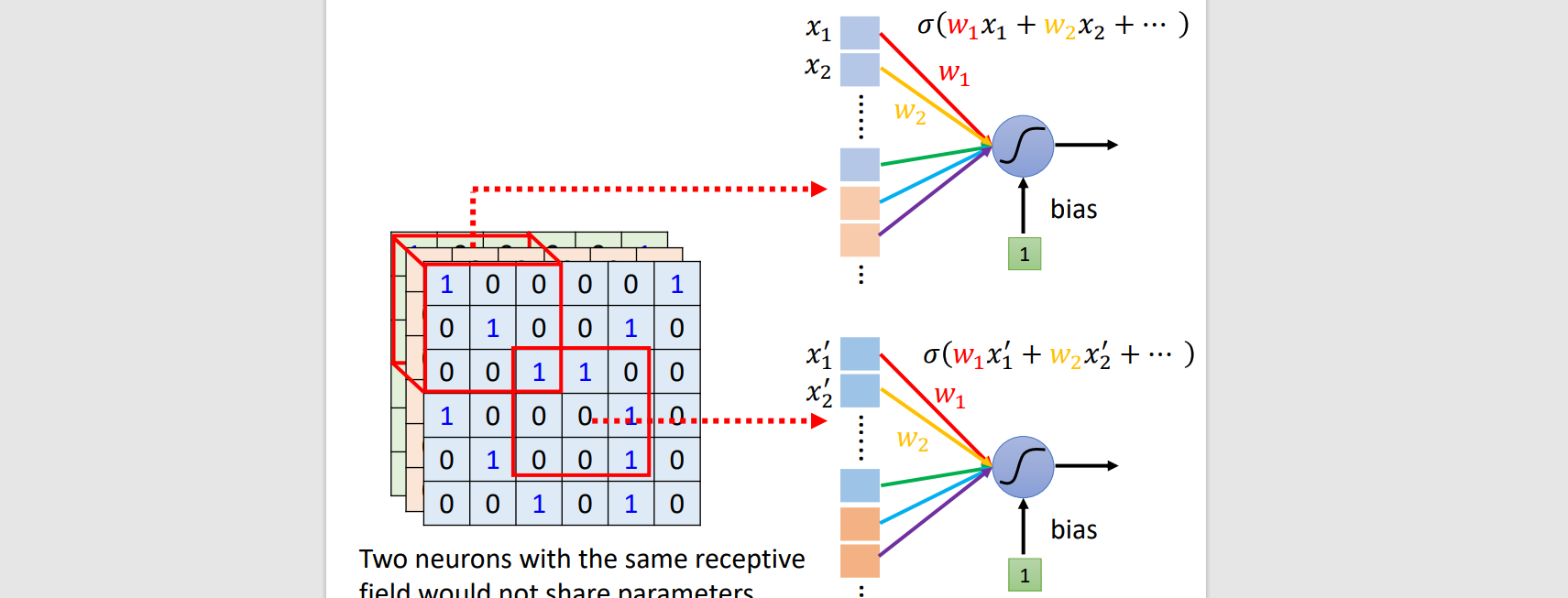
Parameter sharing
Same filter use same parameters. (Input is different, so output is still different)
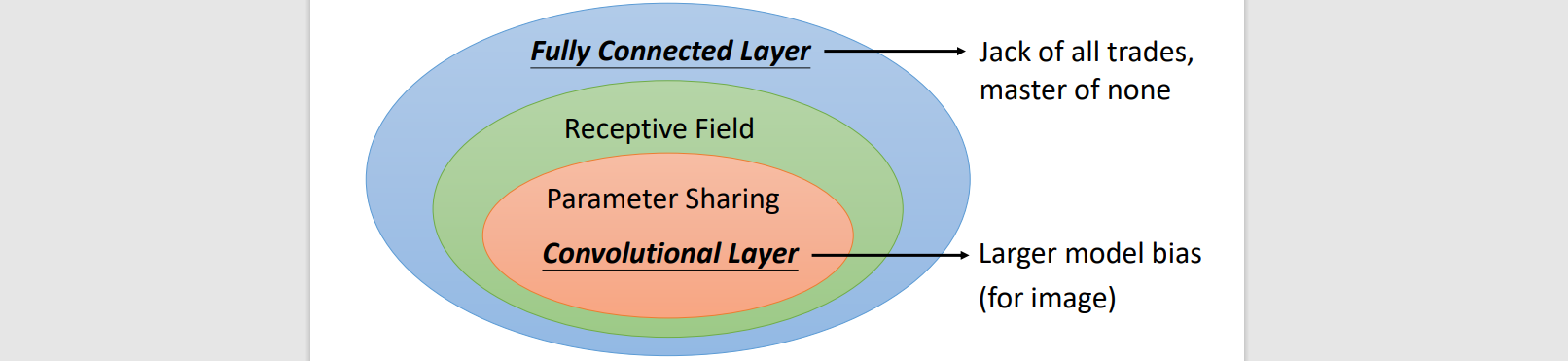
Convolutional Layer
Receptive field + Parameter sharing
Big model bias → low flexibility → less overfitting
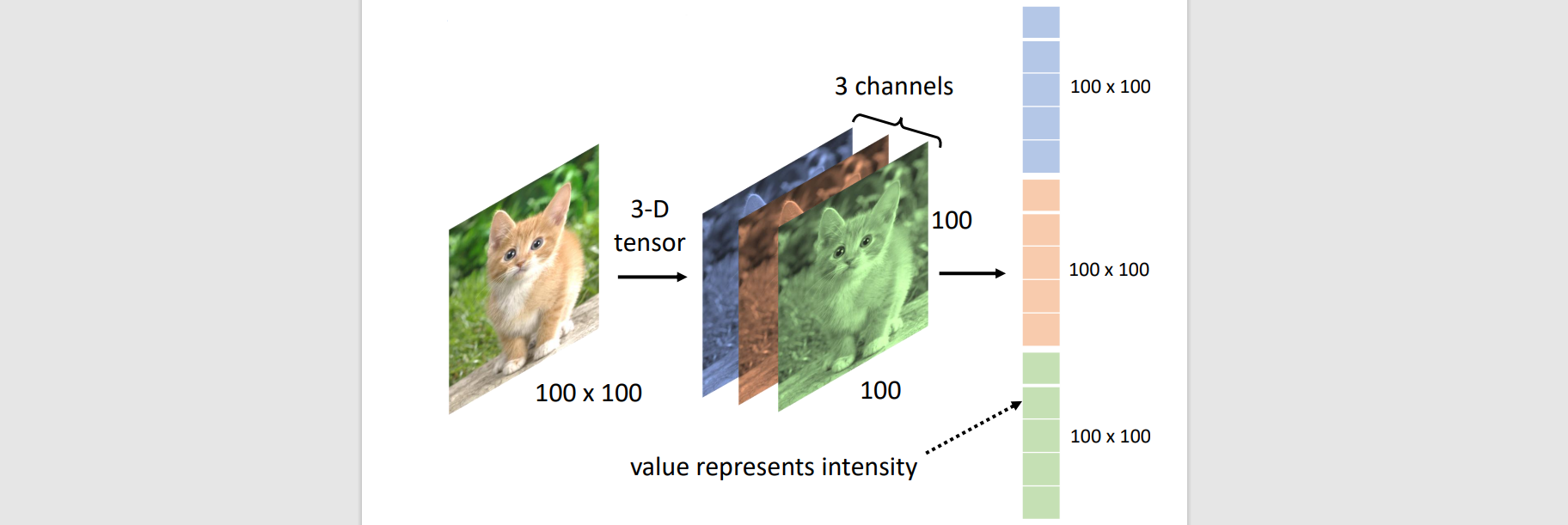
- Colorful: channel = 3
- Black & white: channel = 1
Convolution
- 1st layer: Filter convolute with image → Feature map
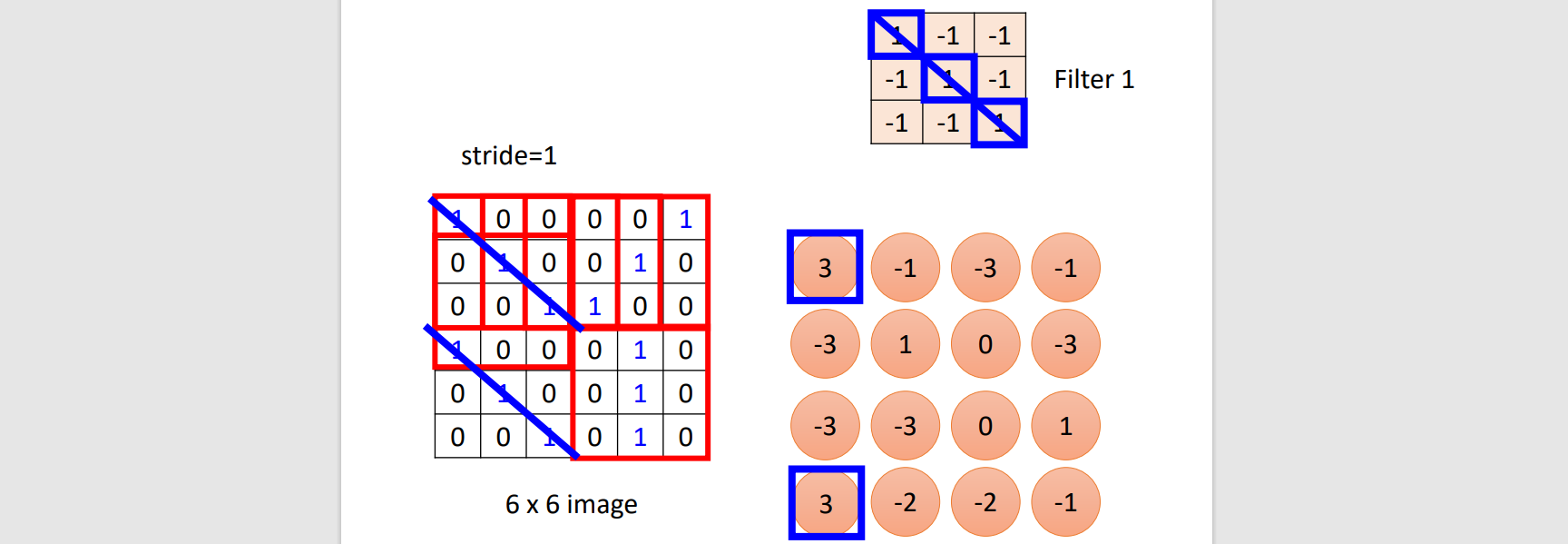
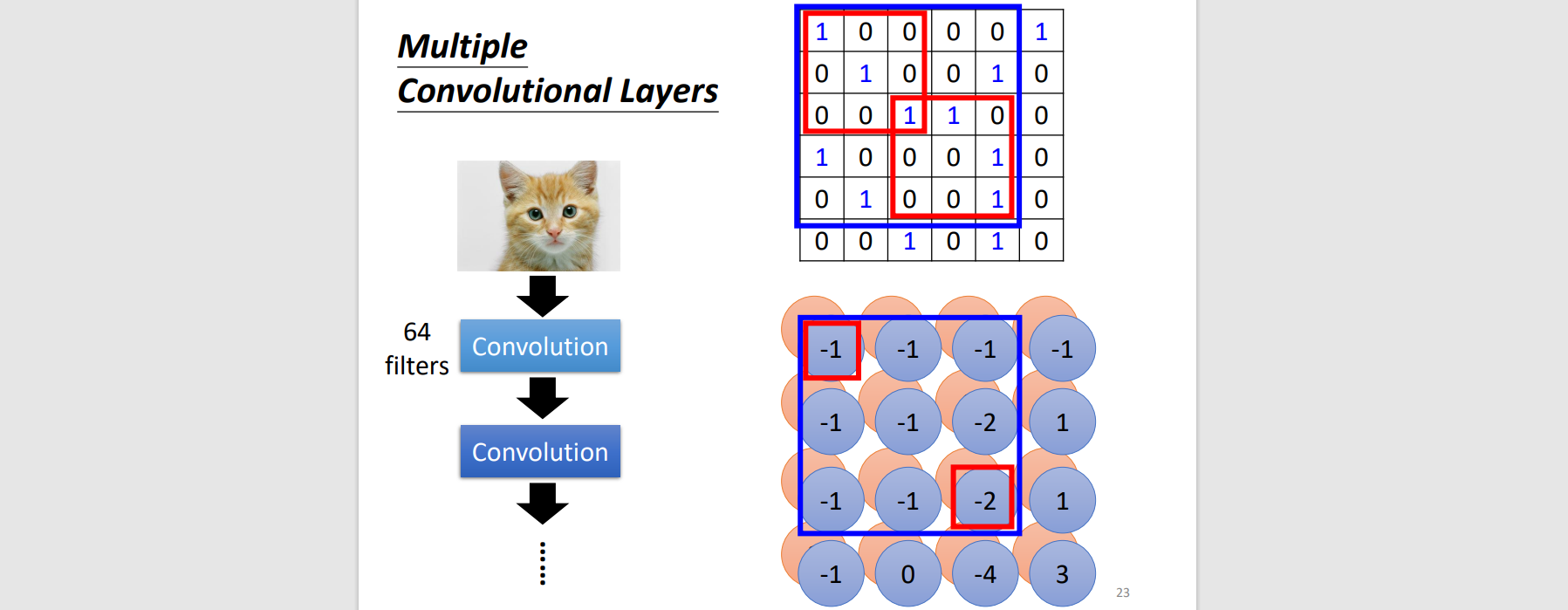
- 2nd layer: Filter convolute with feature map
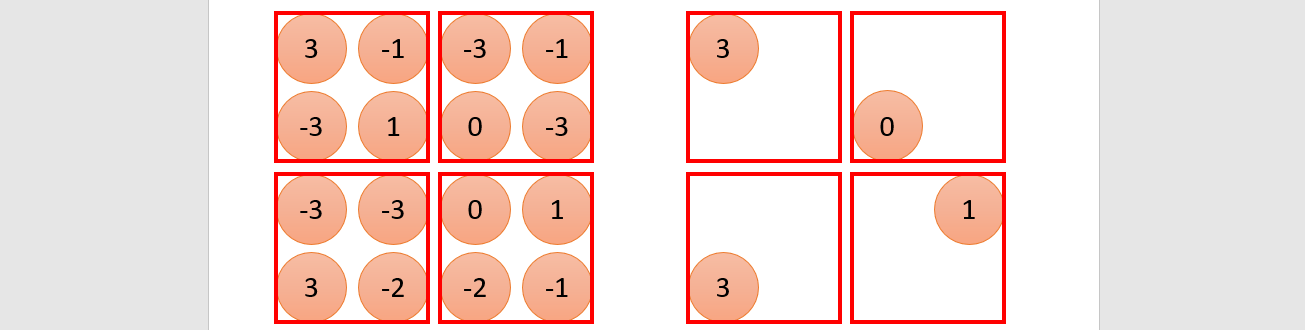
Pooling
After subsampling, the image looks the same

Max pooling
Leave the maximum value
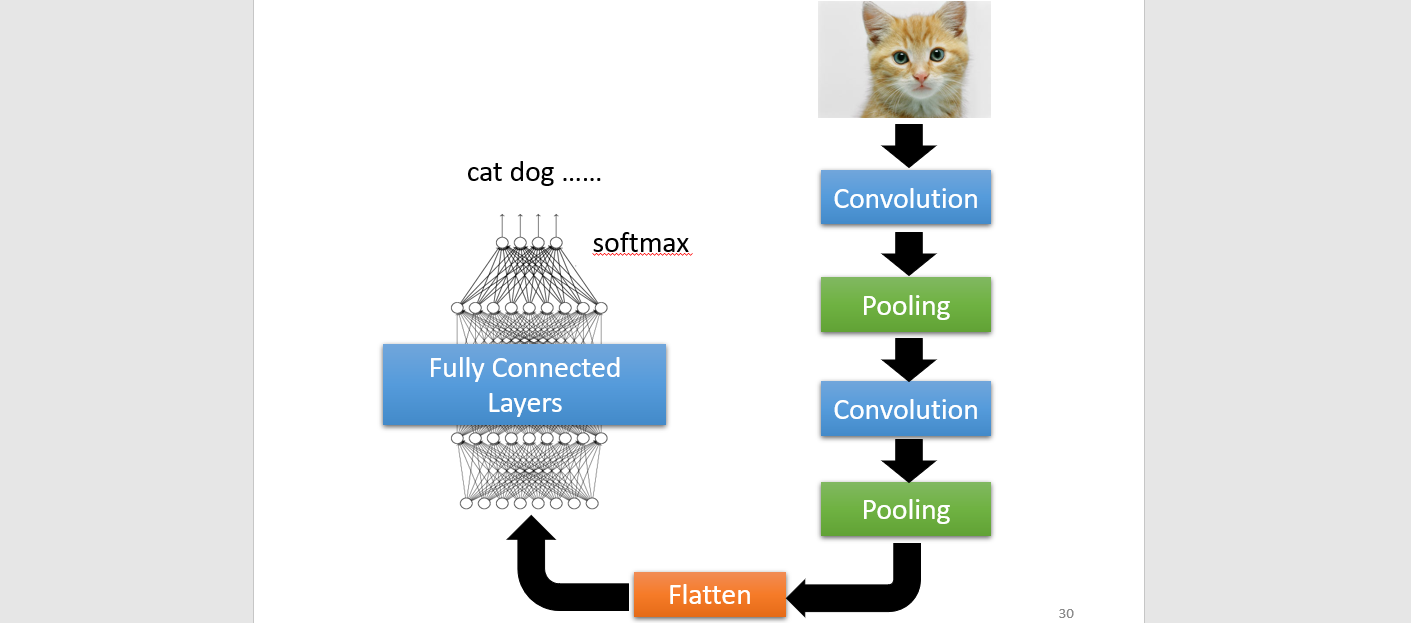
Flatten → 1 dimension
can’t recognize scaling & rotation
Spatial transformation layer → deal with scaling & rotation
Spatial Transformer Layer
Invariant to scaling and rotation
Affine transform
= +