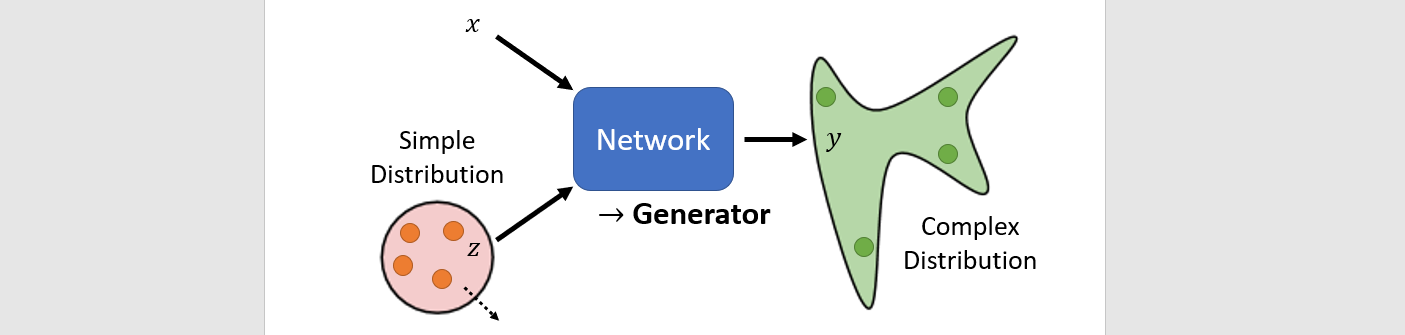
Generative Adversarial Network
- Input: x, z(distribution)
- output: y(complex distribution)
Discriminator

Adversarial (Natural selection)
Generator vs Discriminator
[Fix G, update D] or [Fix D, update G]
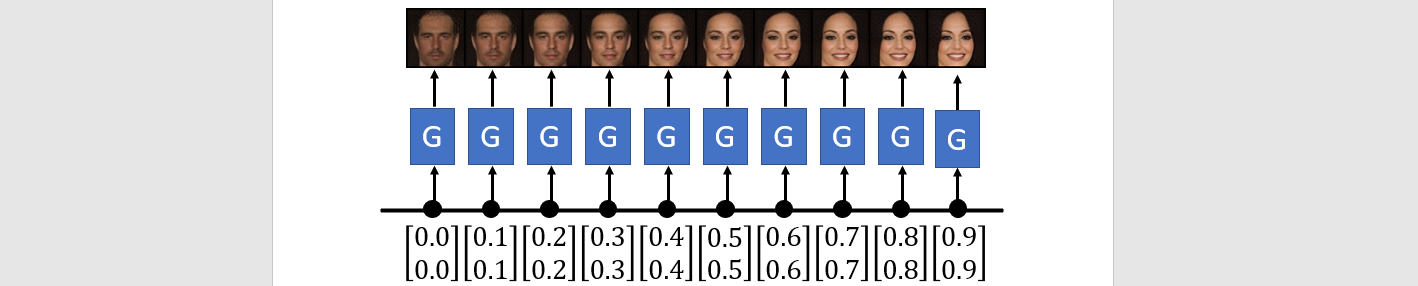
Interpolation
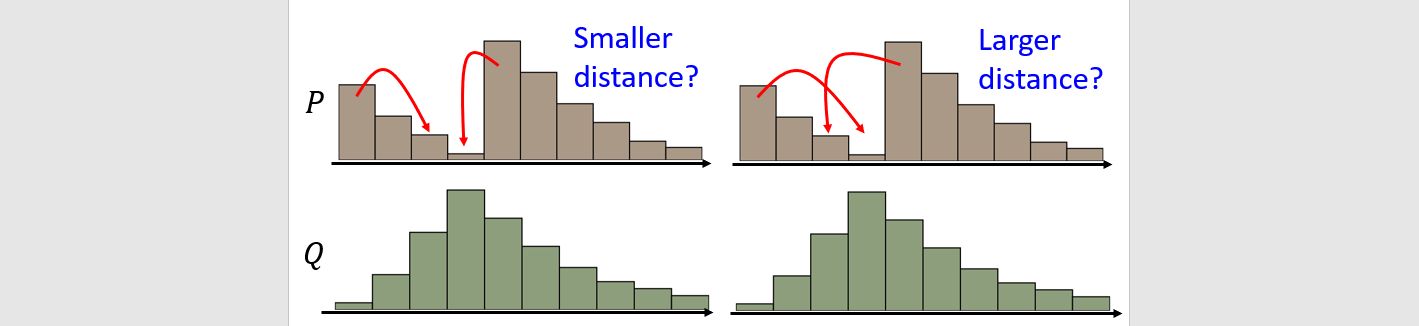
Divergence
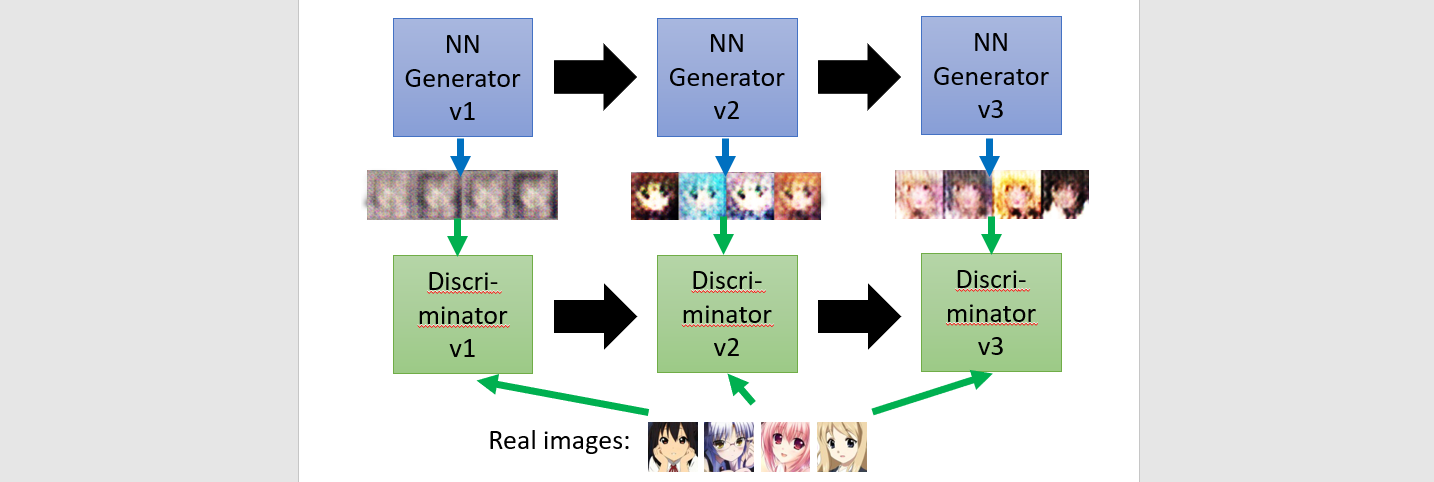
Sampling
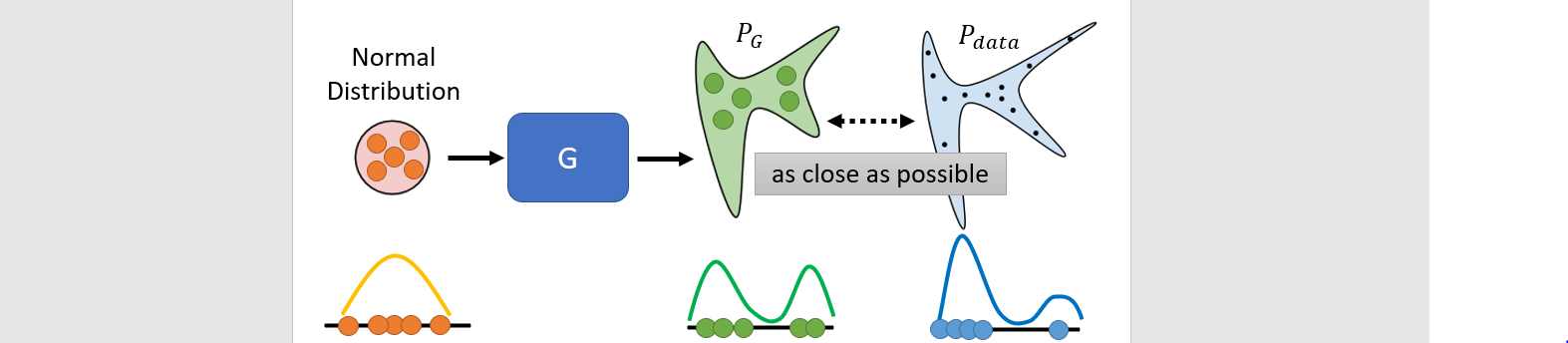
Training:
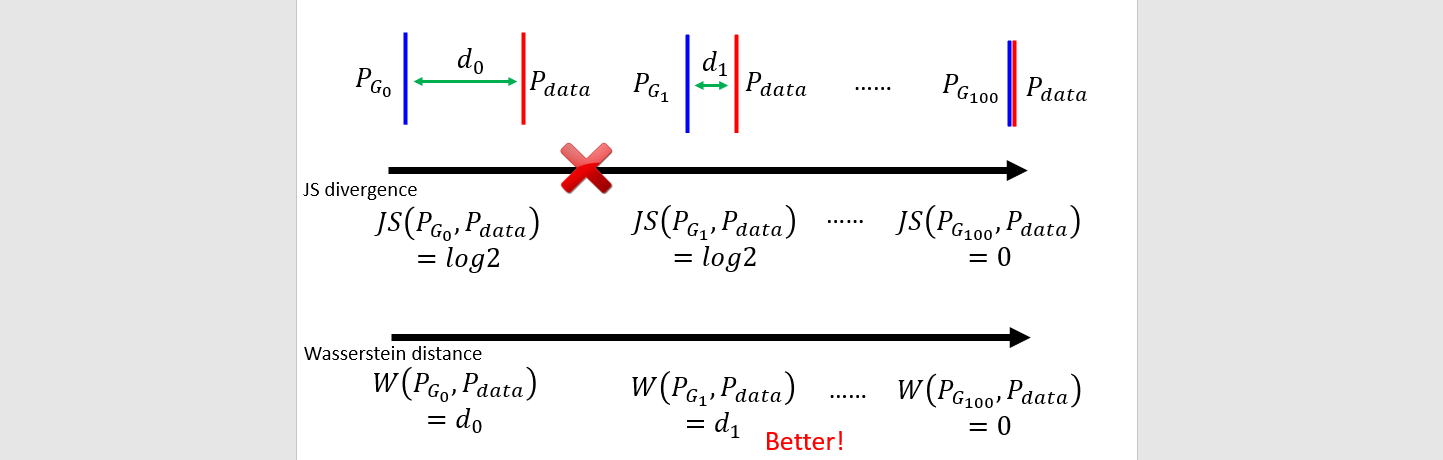
Wasserstein distance
Earth mover

Too many possible moving plans → chose the shortest distance
→ smooth enough
If not 1-Lipschitz
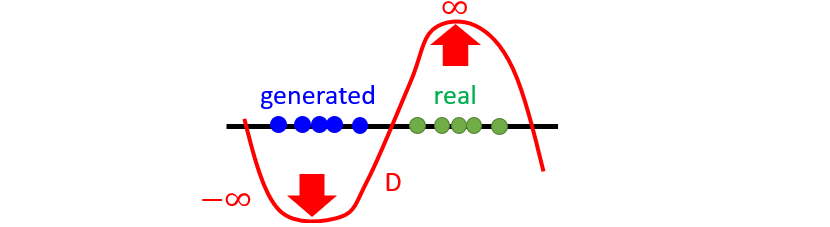
: Expected value of Discriminator from data ()
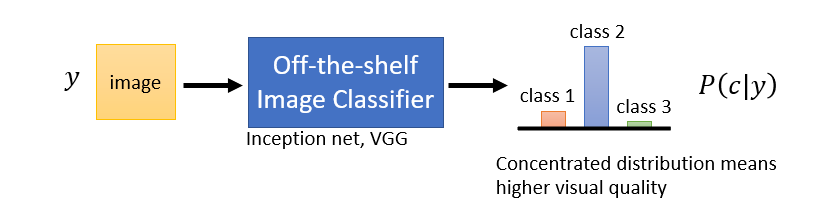
Evaluation
Image classifier
Collapse
- Mode collapse
Too restrict

- Mode dropping
No diversity


- Mode collapse
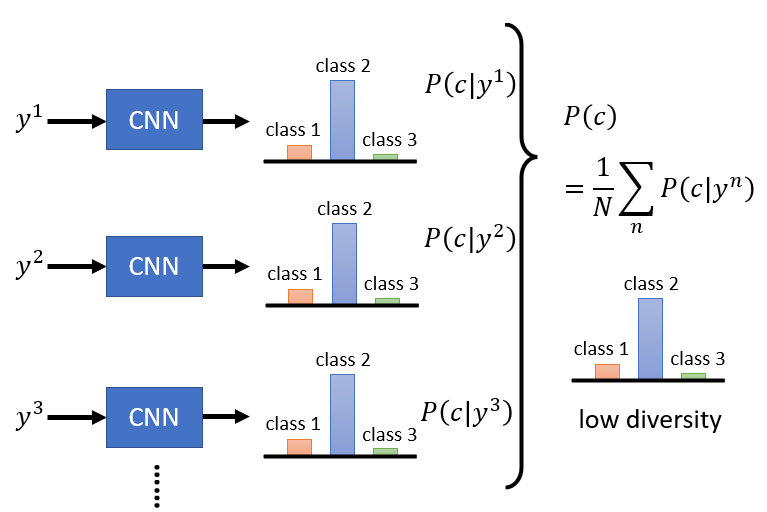
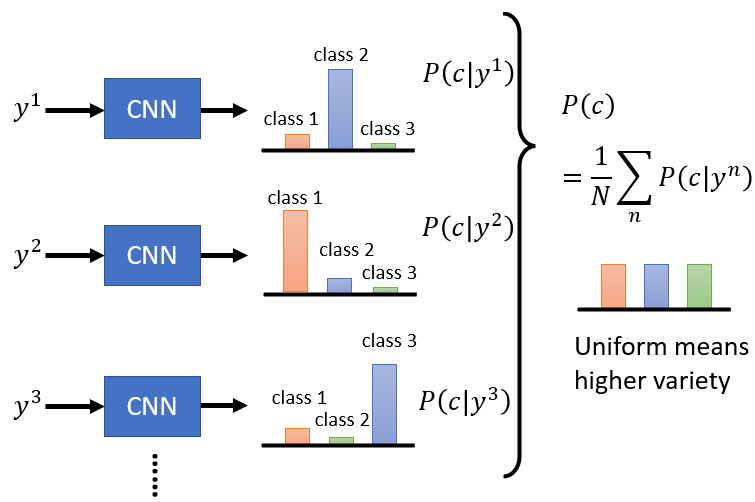
Diversity
- Low diversity
- High diversity
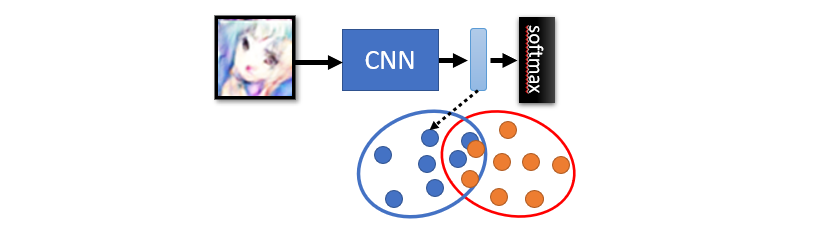
Fréchet inception distance
Calculate differences before softmax
- Low diversity
Conditional generator


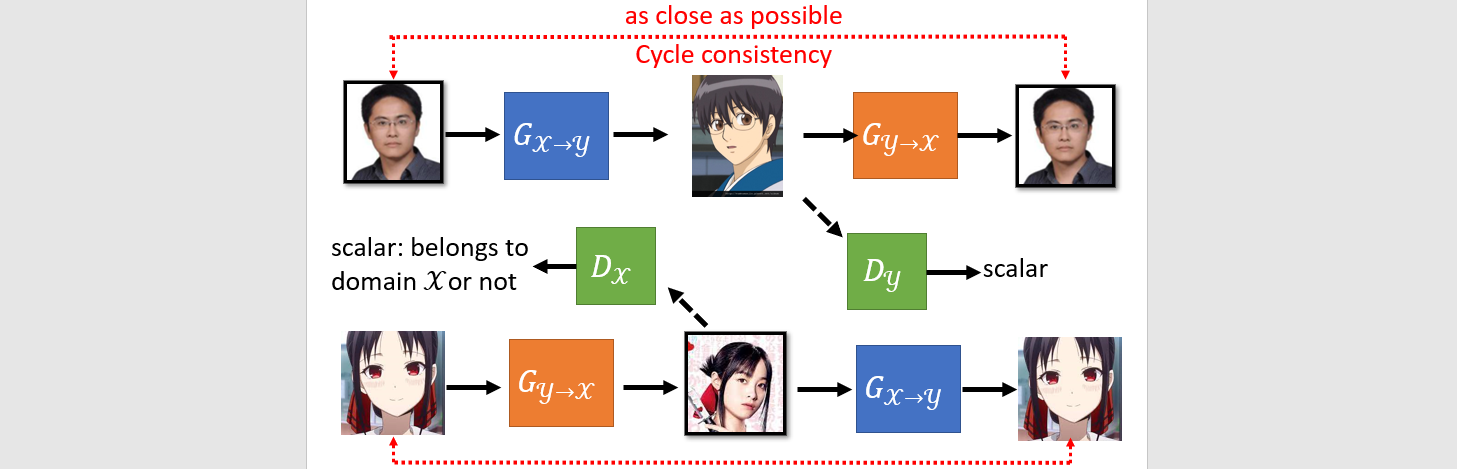
Unpaired data
Unsupervised learning
domain to domain
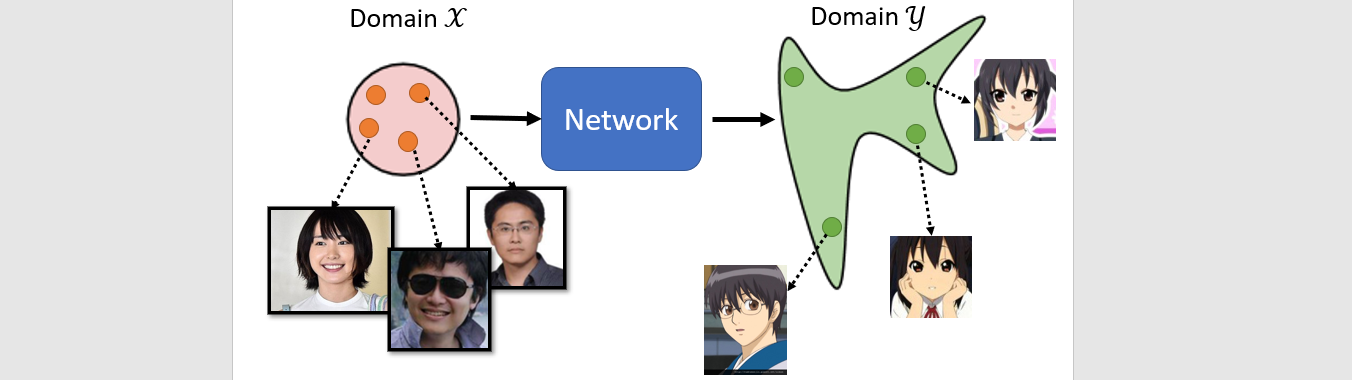
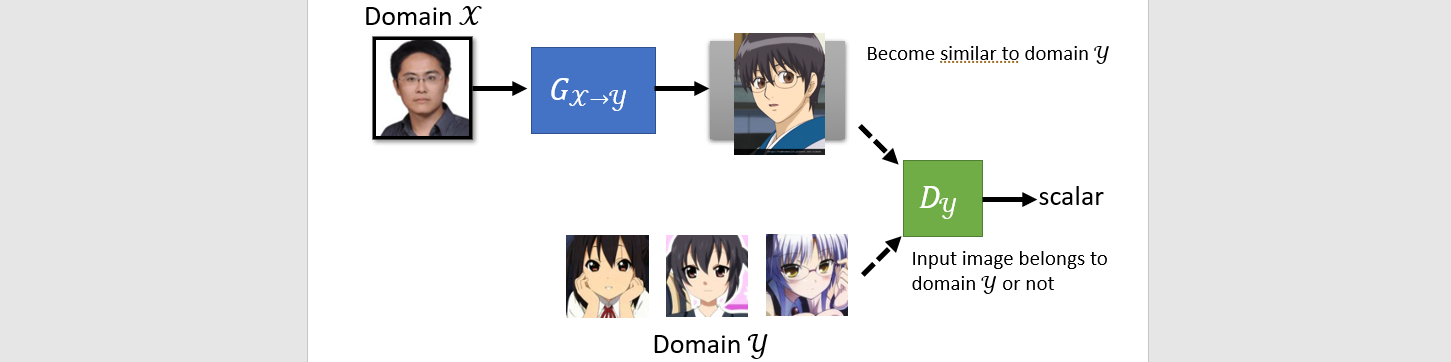
Cycle GAN