Network compression
Smaller model, less parameters.
Network pruning
Reduce parameter
Evaluate the importance of weight/neuron
Fin-tune the network
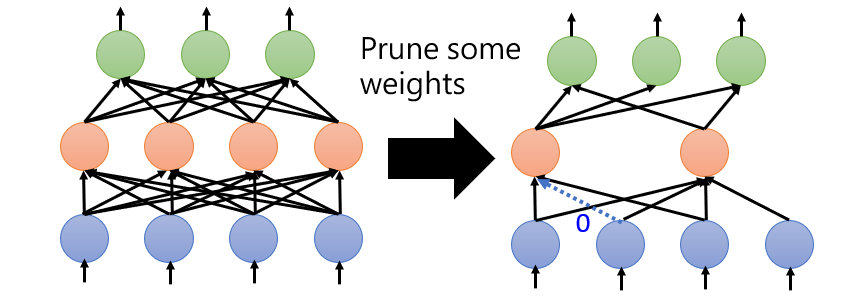
- Weight pruning
Irregular architecture, hard to implement
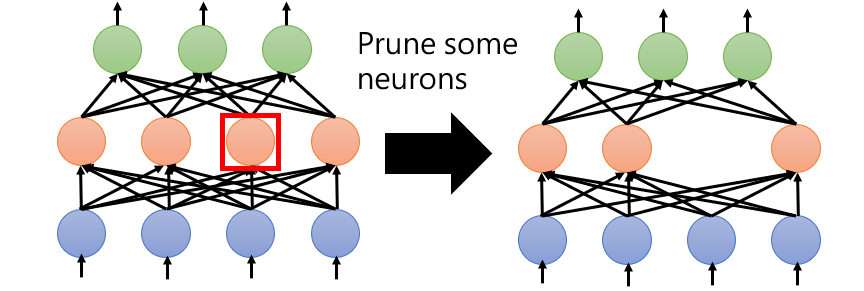
- Neuron pruning
Easy to implement
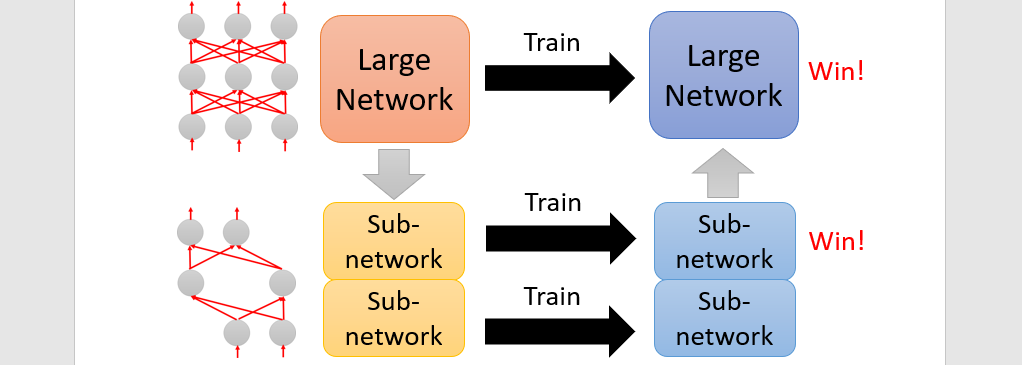
Lottery ticket hypothesis
Knowledge distillation
Student net learn from teacher net
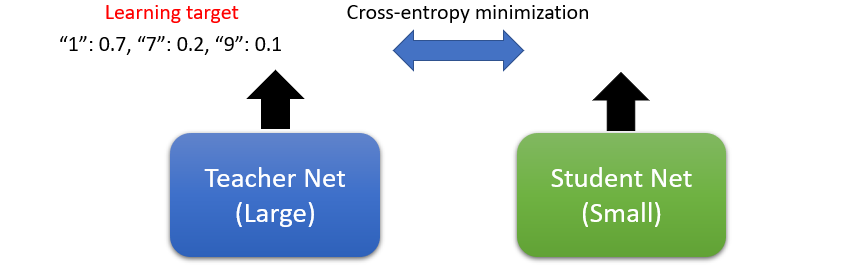
Ensemble:
Average multi-models
Teacher net can be a ensemble

Temperature:
Smoothen softmax
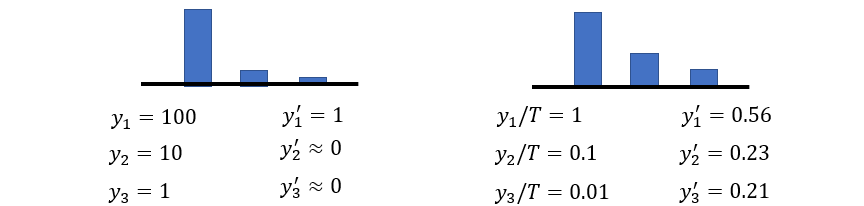
Easy for student to learn
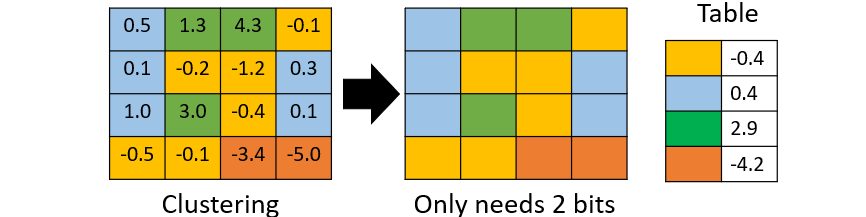
Parameter quantization
Using less bits to present a value
Weight clustering
Binary weights
Weight is either +1 or -1
Prevent overfitting
Huffman encoding
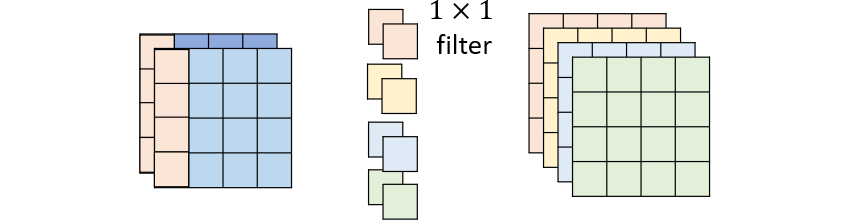
Depthwise separable convolution
- Depthwise
1 channel assigned to 1 filter
Filter number = input channel number
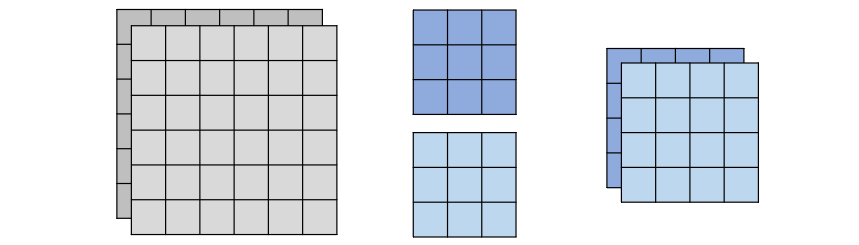
- Pointwise
Filter size = 1x1
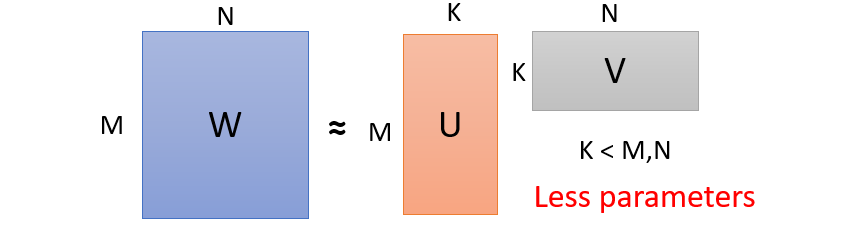
Low rank approximation

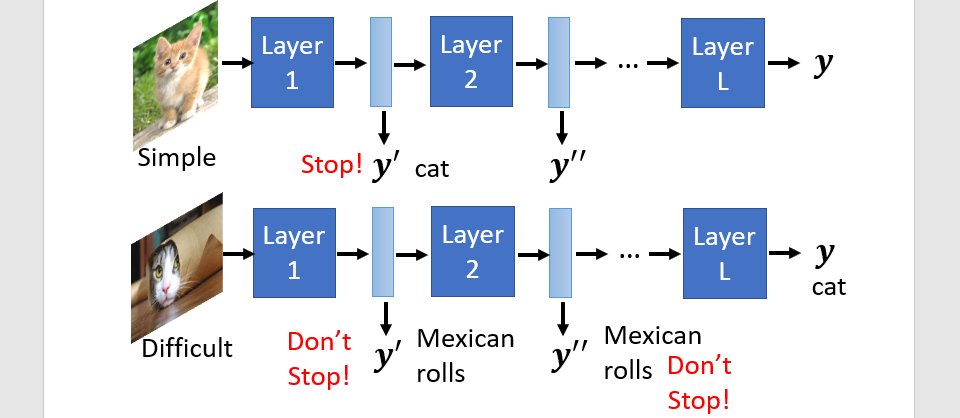
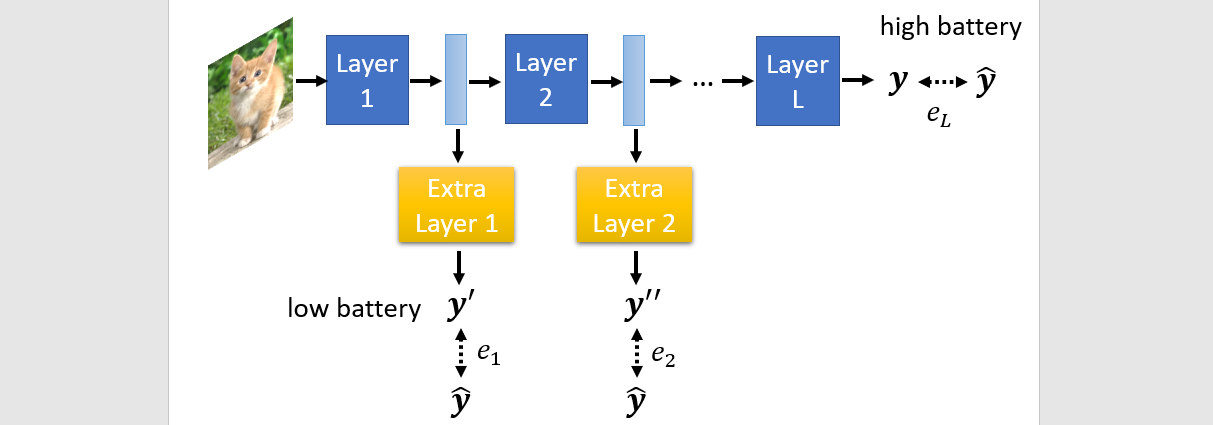
Dynamic computing
The network adjust the required computation
- Dynamic depth
- Dynamic width
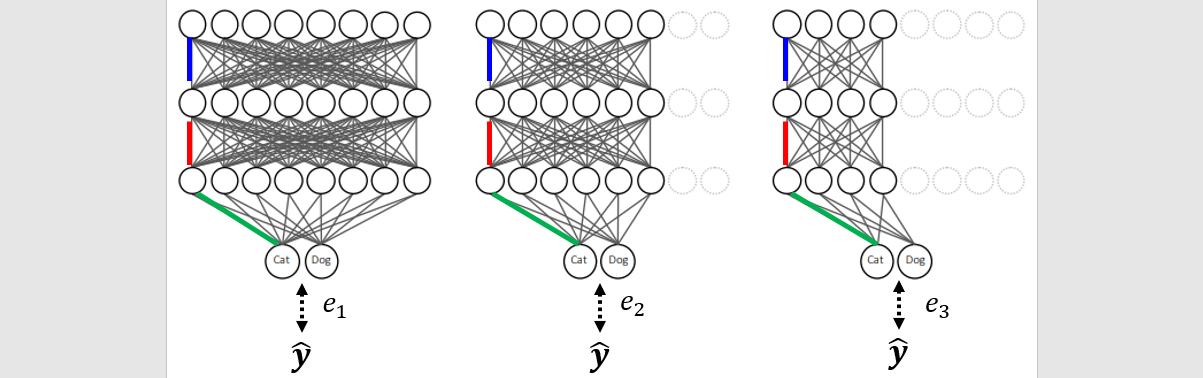
Computation based on sample difficulty