PyTorch
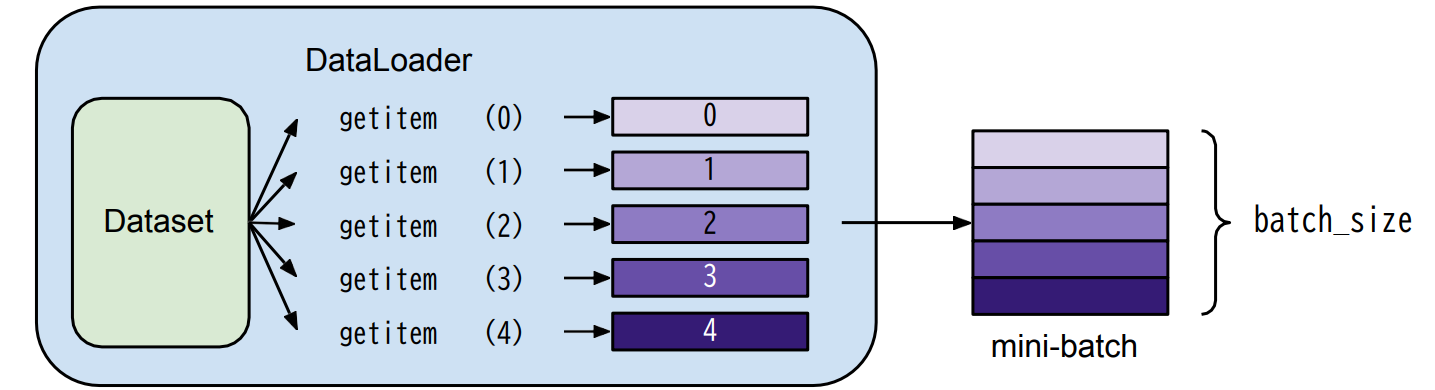
Data
from torch.utils.data import Dataset, DataLoader
dataset = MyDataset(file)
dataloader = DataLoader(dataset, batch_size, shuffle=True) # True: training
# False: testingDataset → stores data samples & expected values(label)
class MyDataset(Dataset):
def __init__(self, X, y = None):
self.data = X
if y is not None:
self.label = torch.LomgTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)Dataloader → groups data in batches enables multiprocessing
Tensor
x = torch.tensor([[], []])
x = torch.from_numpy(np.array([[], []]))
x = torch.zeros([2, 2])
x = torch.ones([1, 2, 5])
y = x.sum()
y = x.mean()
y = x.pow(2)
n = x.shape
x = x.transpose(0, 1) [2, 3] -> [3, 2]
x = x.squeeze(0) [1, 2, 3] -> [2, 3] remove the dimension
x = x.unsqueez(1) [2, 3] -> [2, 1, 3] expand a new dimension
[2, 1, 3]
w = torch.cat([x, y, z], dim=1) [2, 3, 3] -> [2, 6, 3]
[2, 2, 3]
# (3, 4)
t = torch.tensor([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]], dtype=torch.float32)
t1 = t.reshape(2, -1) # -1 -> n
# (2, 6)
[[1, 1, 1, 1, 2, 2], [2, 2, 3, 3, 3, 3]]Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.to('device')Gradient
x = torch.tensor([[1, 0], [-1, 1]], requires_grad=True)
z = x.pow(2).sum()
z.backward()
x.grad
Network Layers
import torch.nn as nnLast dimension must be 32 → ex. (10, 32) (10, 5, 32) (1, 1, 3, 32)
- Linear (fully-connected)

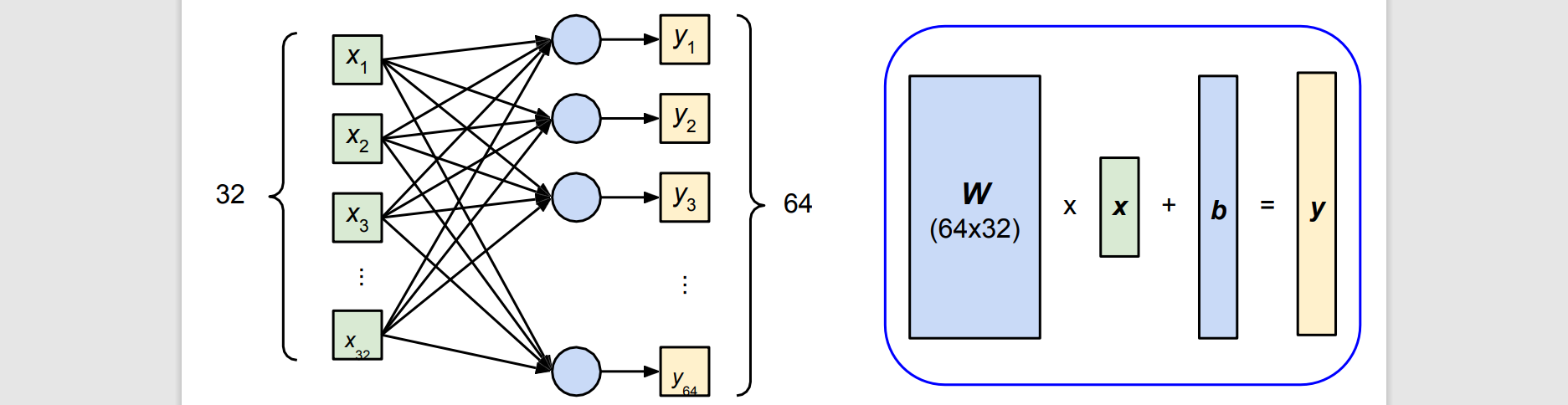
layer - torch.nn.Linear(32, 64) layer.weight.shape # (64, 32) layer.bias.shape # (64)
- Sigmoid/ReLU
Model
class MyModel(nn.Module): def __init__(self): super(MyModel, self).init() # init nn.Module self.net = nn.Sequential( nn.Linear(10, 32), # Input data is (* x 32) nn.Sigmoid(), # Piecewise linear ) def forward(self, x): return self.net(x)self.layer1 = nn.linear(10, 32) self.layer2 = nn.Sigmoid() out = self.layer1(x) out = self.layer2(out) return out
Loss
criterion = nn.MSELoss() criterion = nn.CrossEntropyLoss() loss = criterion(model_output, expected_value)
Optimization
Stochastic Gradient Descent
optimizer = torch.optim.SDG(model.parameters(), lr, momentum=0)
optimizer.zero_grad() # reset gradients of model parameters
loss.backward() # backpropagate gradients of prediction loss
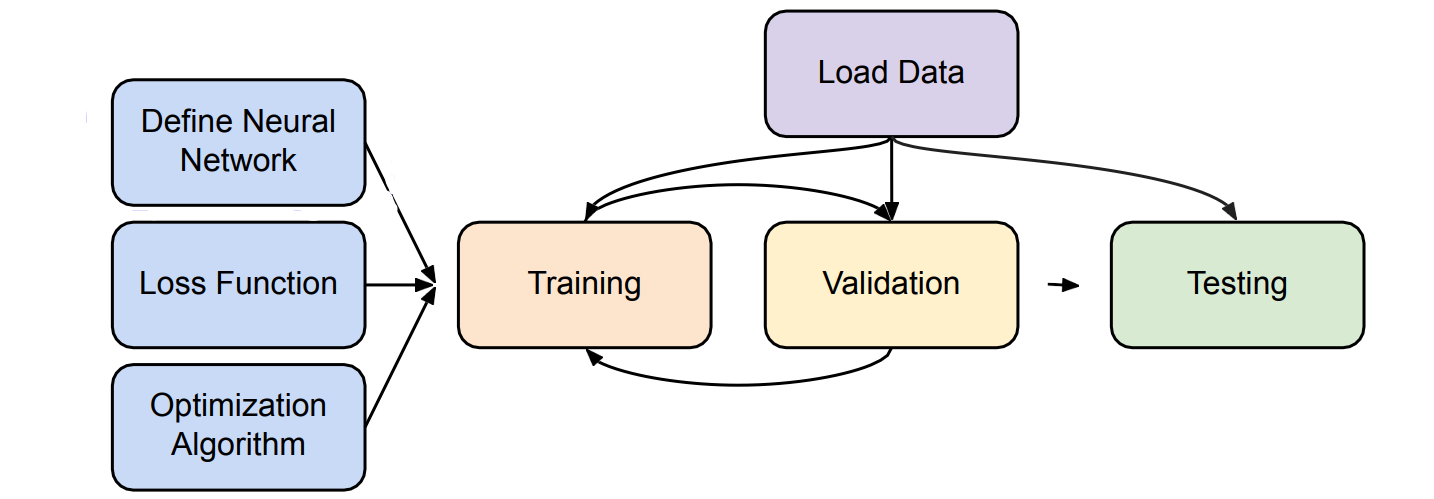
optimizer.step() # adjust model parametersTraining
setup
dataset = MyDataset(file) # read data tr_set = DataLoader(dataset, 16, shuffle=True) # batch model = Model().to(device) # construct model to device(cpu/cuda) criterion = nn.MSELoss() # set loss function optimizer = torch.optim.SDG(model.parameters(), 0.1) # optimizer
Training loop
for epoch in range(n_epochs): model.train() # set to training mode for x, y in tr_set: optimizer.zero_grad() x, y = x.to(device), y.to(device) pred = model(x) # forward pass (compute output) loss = criterion(pred, y) # compute loss loss.backward() # compute gradient (backpropagation) optimizer.setup() # update model with the optimizer
Validation loop
model.eval() # set to evaluation mode(prevent accidental training) total_loss = 0 for x, y in dv_set: x, y = x.to(device), y.to(device) with torch.no_grad(): # disable gradient calculation pred = model(x) loss = criterion(pred, y) total_loss += loss.cpu().item() * len(x) # accumulate loss avg_loss = total_loss / len(dv_set.dataset)
Testing loop
model.eval() # add dropout, batch normalization preds = [] for x in tt_set: x = x.to(device) with torch.no_grad(): pred = model(x) # GPU tensor cannot convert to numpy preds.append(pred.cpu()) # change to CPU, then .item()
Save/Load models
- save
torch.save(model.state_dict(), path)
- load
ckpt = torch.load(path) model.load_state_dict(ckpt)
- save
Transformer
import torchvision.transforms as transforms# resize PIL images
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])Augmentation
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])CNN
# torch.n.Conv2d(in_channel, out_channel, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
)Learning rate scheduling
from torch.optim import Optimizer
from torch.optim.lr_scheduler import LambdaLR
def get_cosine_schedule_with_warmup(
optimizer: Optimizer,
num_warmup_steps: int,
num_training_steps: int,
num_cycles: float = 0.5,
last_epoch: int = -1,
):
def lr_lambda(current_step):
# Warmup
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
# decadence
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
# implement learning rate
return LambdaLR(optimizer, lr_lambda, last_epoch)
Reinforcement Learning
import gymDiscrete(n) -> n kinds of actions
initial_state = env.reset()
action = env.action_space.sample() -> random
observation(state), reward, done(True/False), info = env.step(action)Generative
import einops (support flexible tensor operations)