Reinforcement learning
Overview
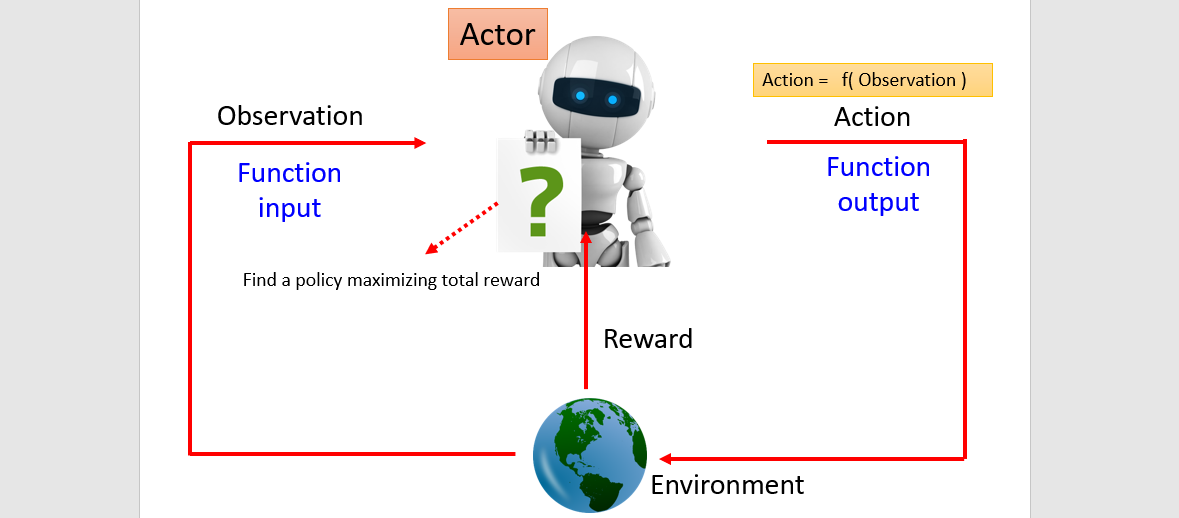
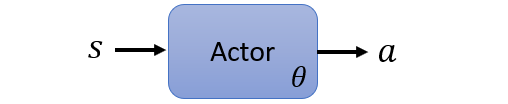
: observation, : action, : parameter, : cumulated reward, : policy(network), : reward
: trajectory, : advantage function
(random)
(Expected Reward) cannot calculate → sampling
Reward delay: sacrifice immediate reward to gain long-term reward
Cumulated reward
Cumulated reward(based on distance)
()
Policy gradient
Add baseline to avoid always positive
Assign suitable credit
discount factor , futher the smaller impact
- On-policy: an actor for training & interacting is the same
- Off-policy: an actor for training & interacting is different
- Proximal policy optimization(PPO)
Exploration: the actor needs randomness during data collection
- On-policy: an actor for training & interacting is the same
Actor-critic
Value function :
- Monte-Carlo based approach(MC)
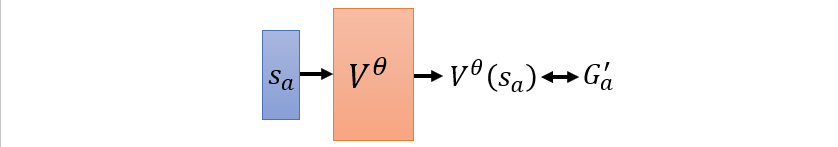
- Temporal-difference approach(TD)
⋯⋯
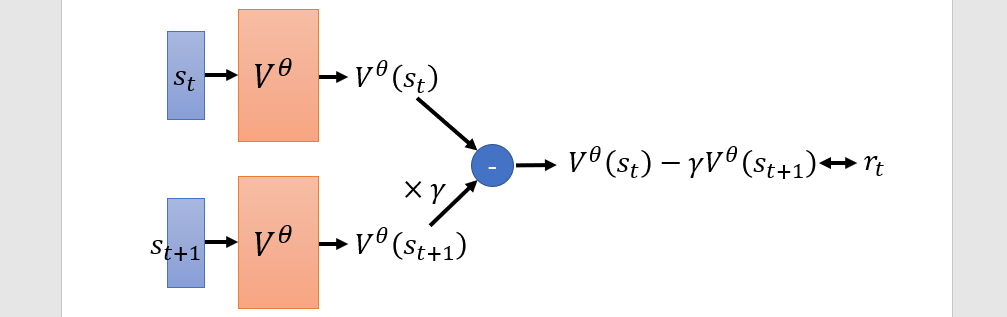
Shared parameter
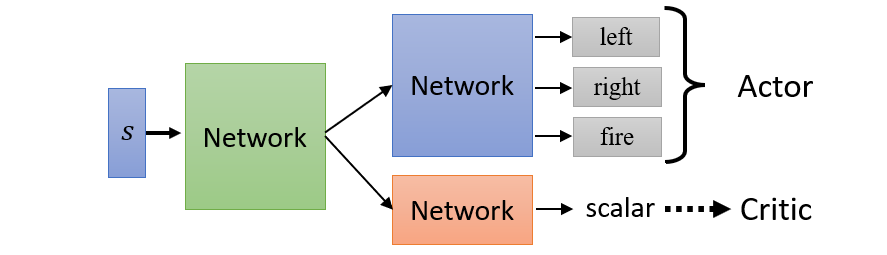
- Monte-Carlo based approach(MC)
Reward shaping
Define extra reward to guide agents
Curiosity based → see new meaningful things
No reward
Learn from demonstration
- Imitation learning
- Inverse reinforcement learning(IRL)
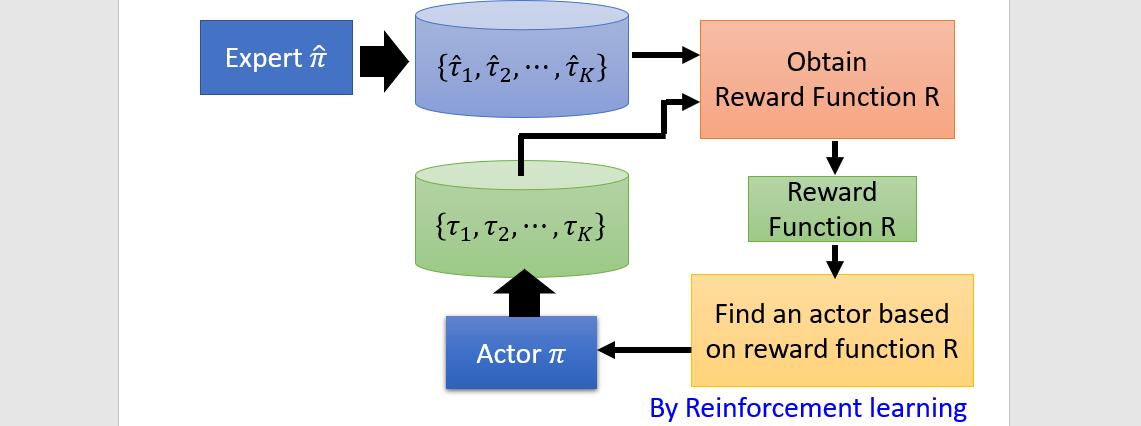
Actor → Generator, Reward function → Discriminator
Q-learning
Environment
environment state: invisible to the agent
Reward
Specify the goal
Agent
Agent state
a function of history. agent’s actions depend on state
- History: full sequence of observations, actions, rewards. Used to construct agent state.
- Markov Decision Process: adding more history does not help.
= = Environment state (sees everything)
💡t: time step
u(): state update function- Last observation: (not enough)
- Complete history: (too large)
- A generic update:
Policy
define agent’s behavior.
Deterministic policy:
Stochastic policy:
Value functions
select between actions, evaluate desirable state.
- Depends on policy
- Recursive form
Bellman equation
💡discount factor
immediate vs long-term
rewards trade-off
Model
Predict what the environment will do next
- predict next state:
- predict next (immediate) reward:
- predict next state:
categories
- Value based: value function
- Policy based: policy
- Actor critic: value function + policy
- Model free: No model
- Model based: model
- Learning: environments are initially unknown
- Planning: environments are known
- Prediction: predict the future
- Control: optimize the future