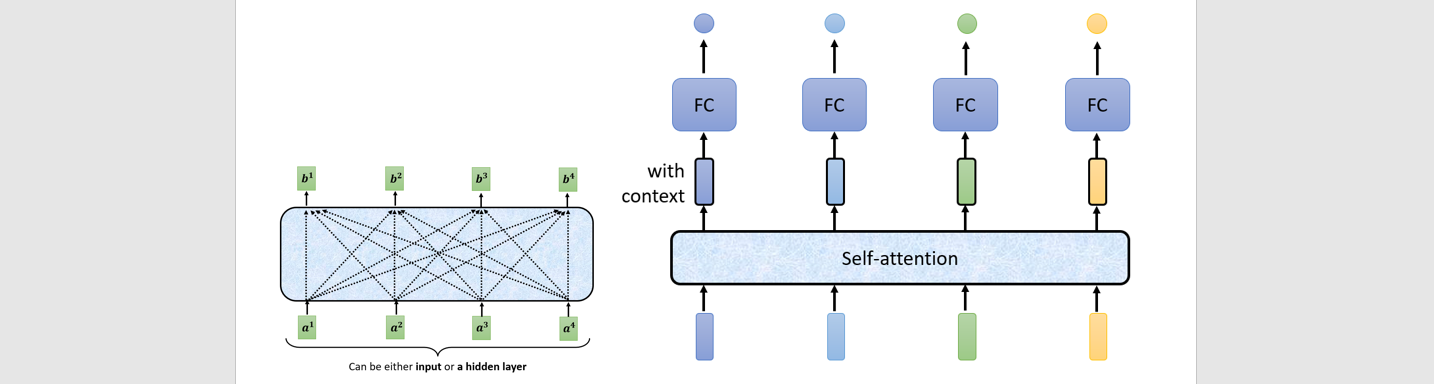
Self-attention
Allows the inputs to interact with each other (“self”)
and find out who they should pay more attention to
Numbers of input vector are not fixed → words/voice/graph process
Fully connected network
General Transformer
Types



Self attention
capture dependencies and relationships within input sequences
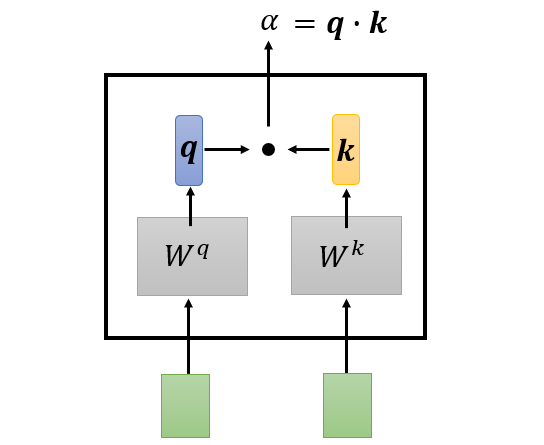
- Dot product
- Additive
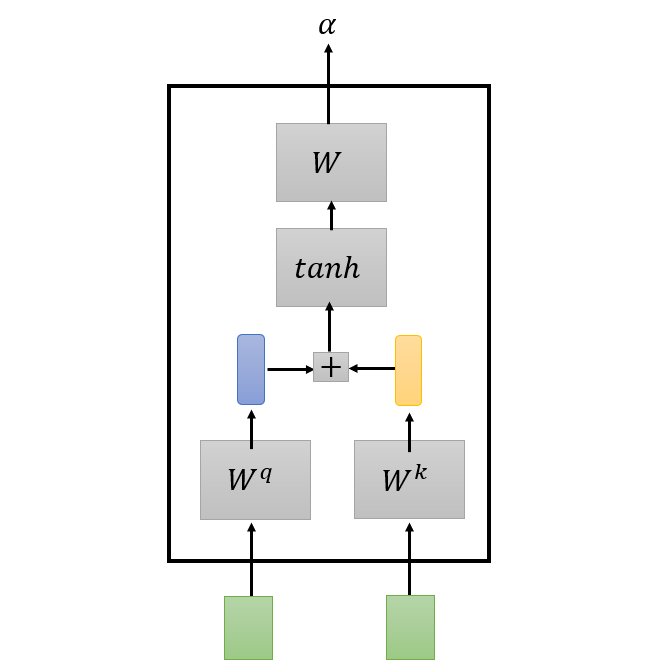
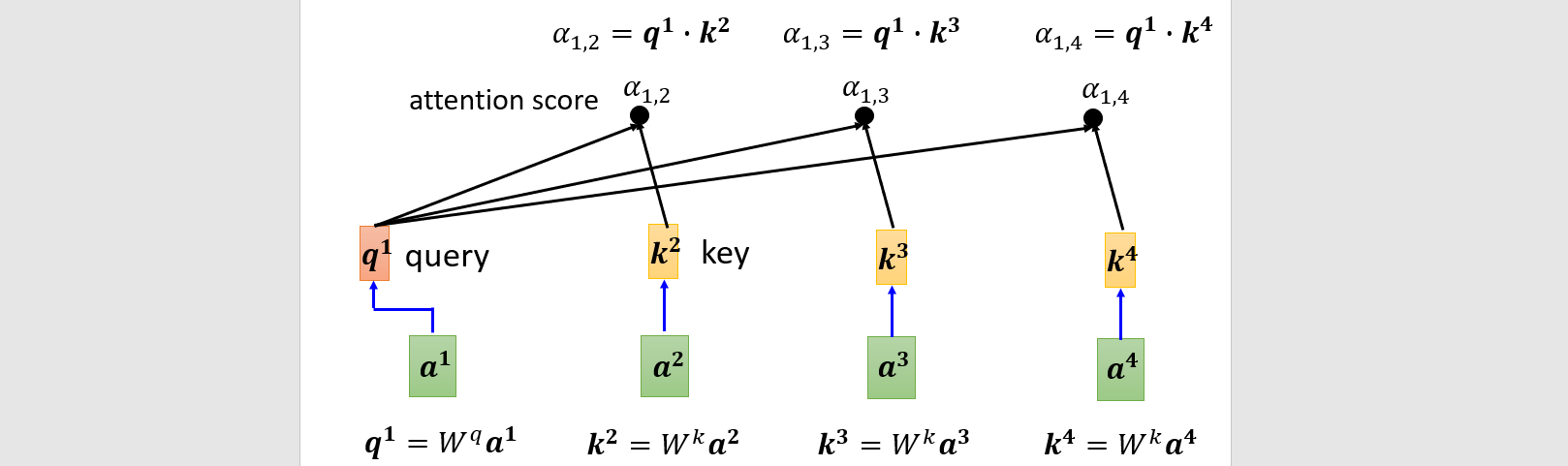
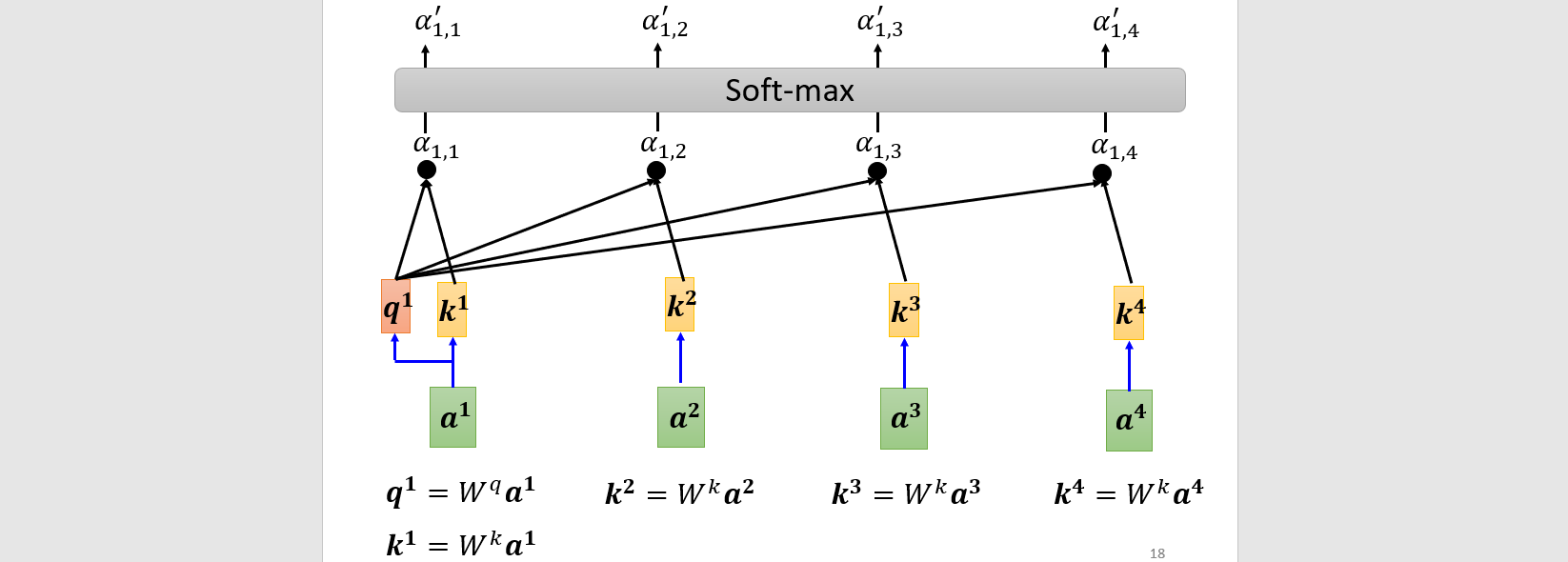
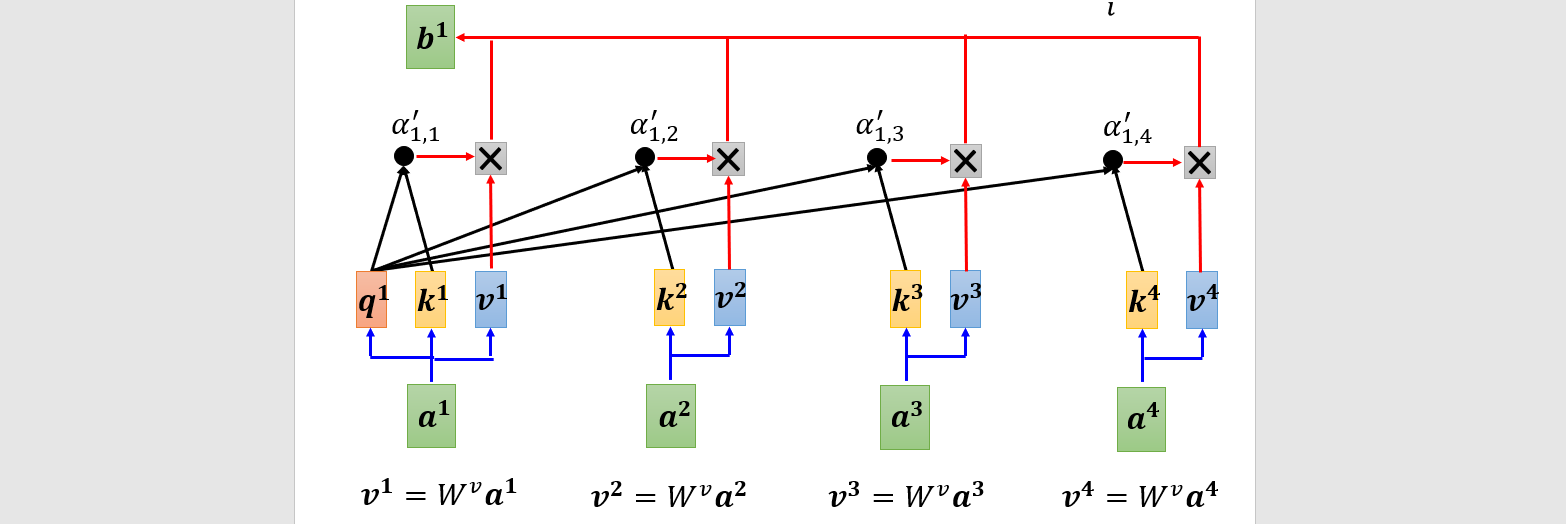

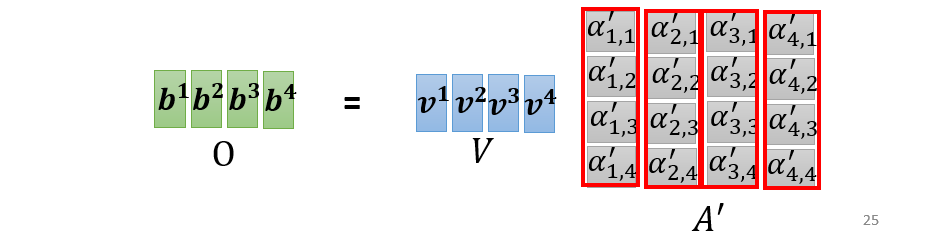
Multi-head self-attention
Positional Encoding
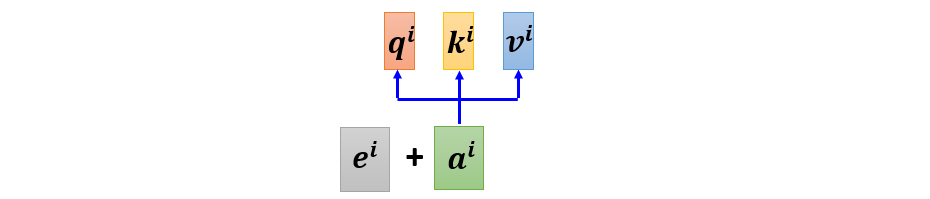
Positional vector
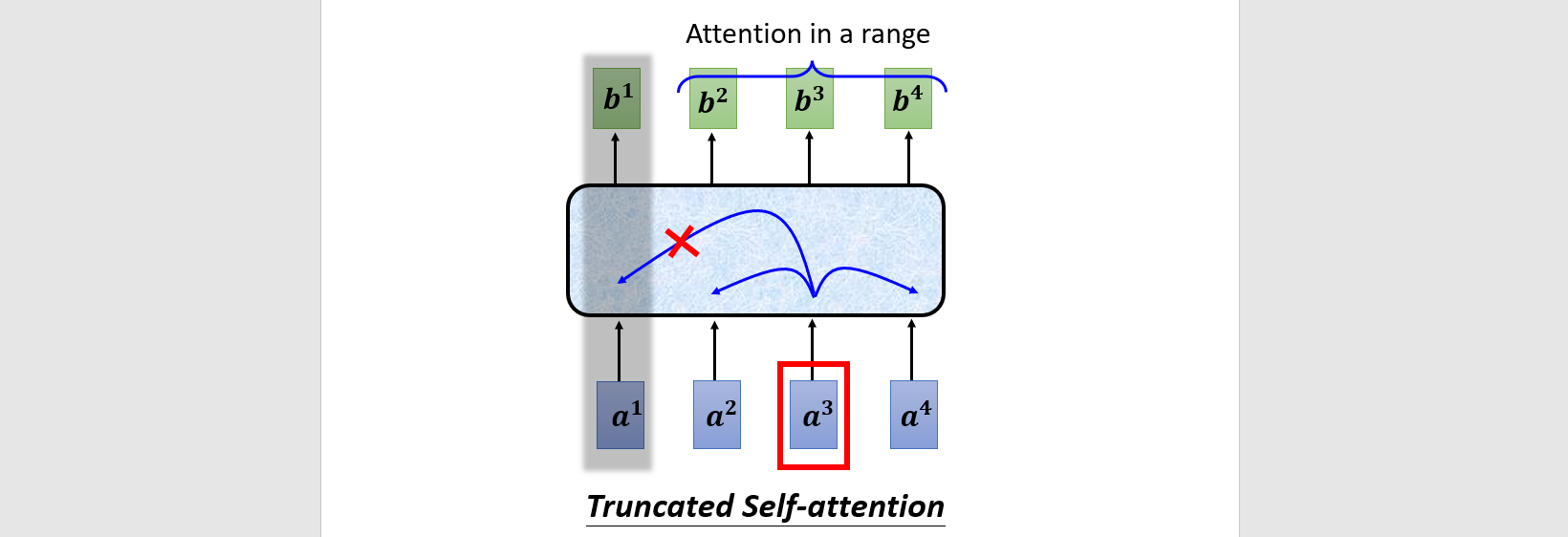
Truncated self-attention
Recurrent Neural Network
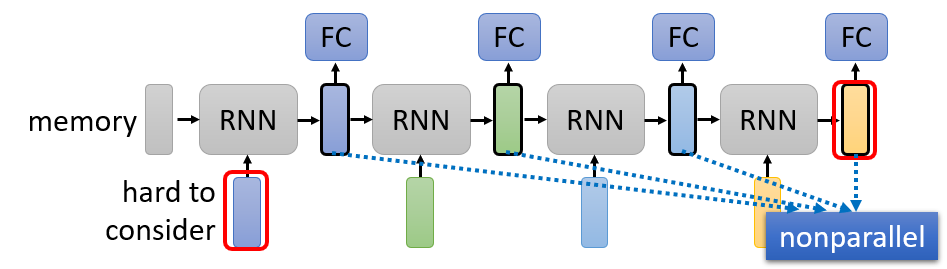
Self-attention is better
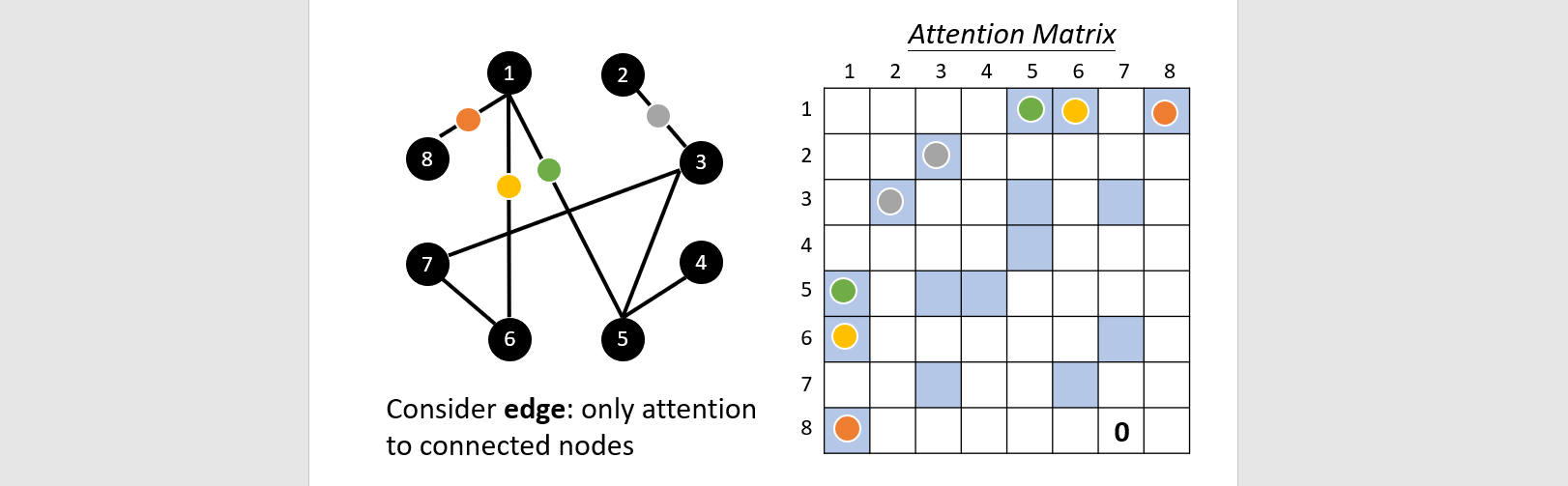
Graph Neural Network
Graph → Matrix → Vector