Self-supervised learning
- Supervised
Labeled
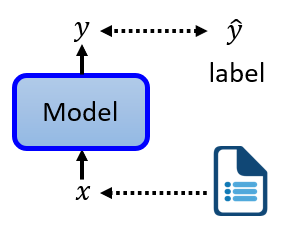
- Self-supervised
No label
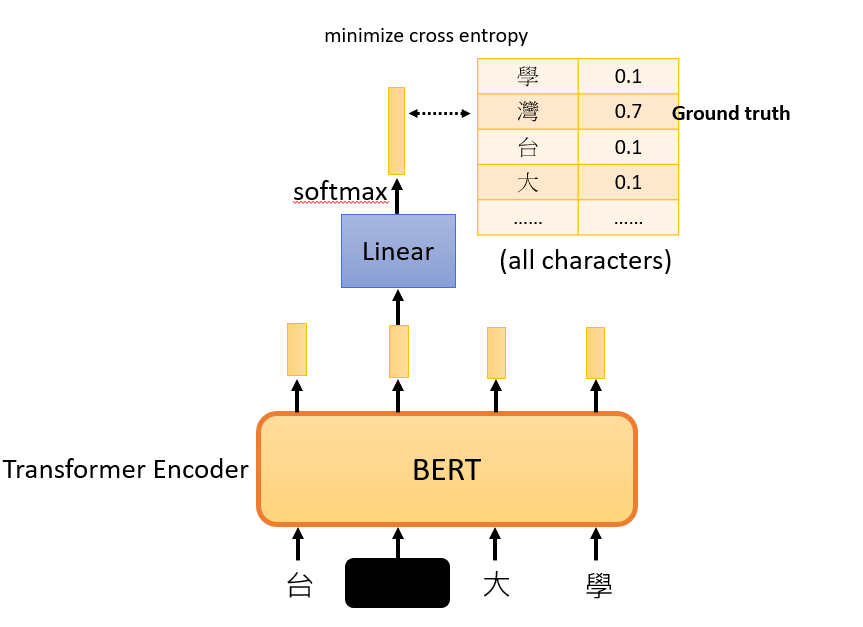
Bidirectional Encoder Representations from Transformers (BERT)
Transformer encoder. Like a cloze test.
Masking input
Randomly mask some tokens(mask or replace with a random token)
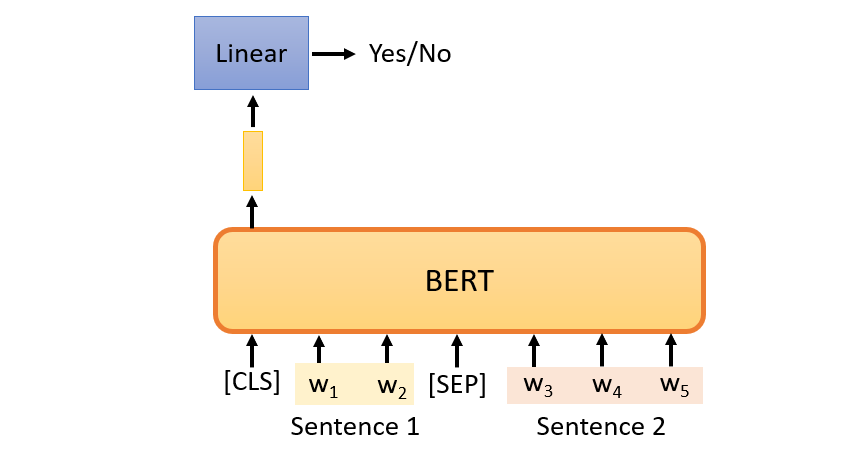
Next sentence prediction
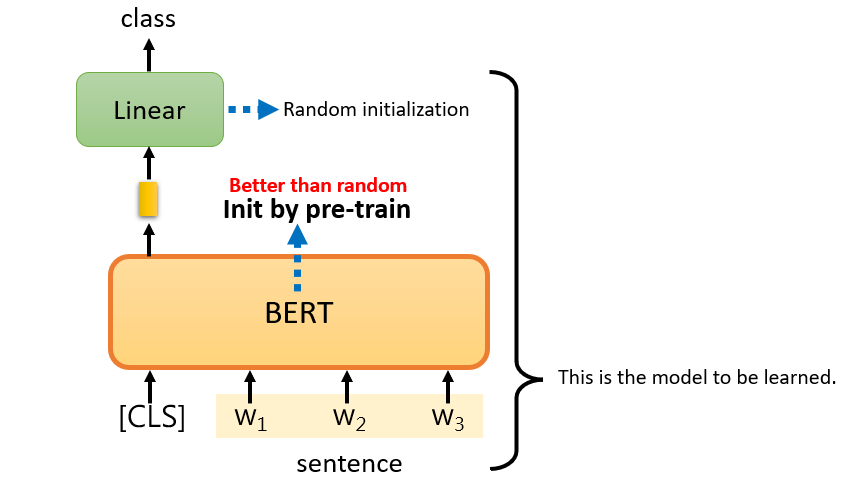
Fine-tune
Train pre-trained BERT with new data
General Language Understanding Evaluation (GLUE score)
Fine-tune follow GLUE score to optimize BERT
- Sentiment analysis
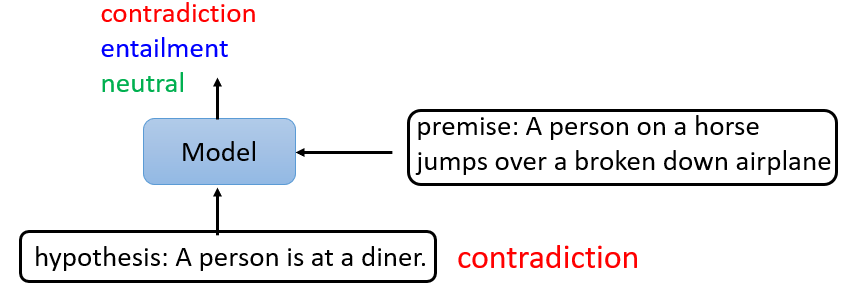
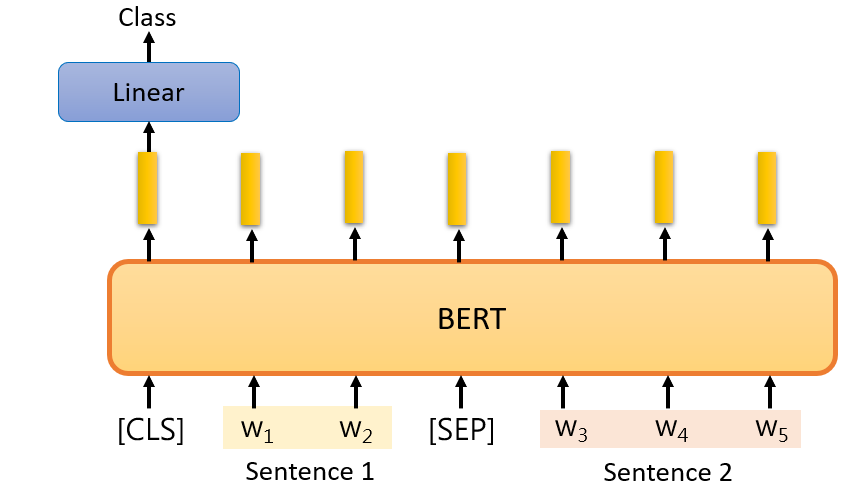
- Natural Language Inference (NLI)
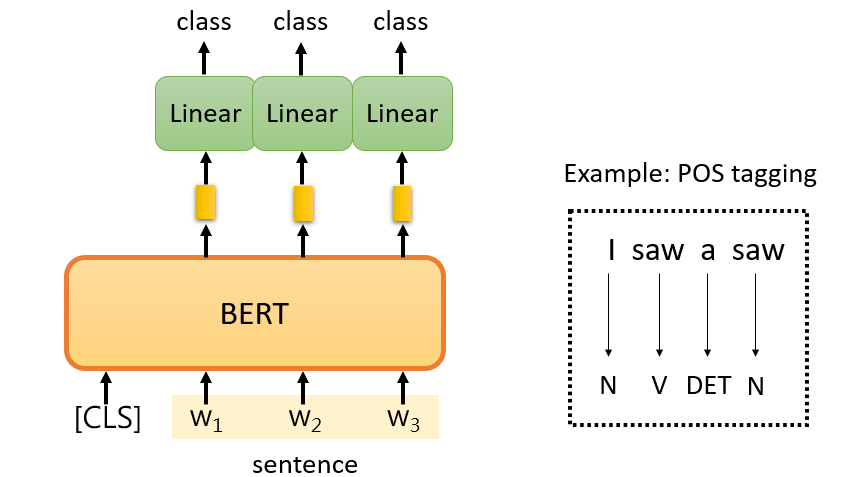
- Part-of-speech tagging (POS)
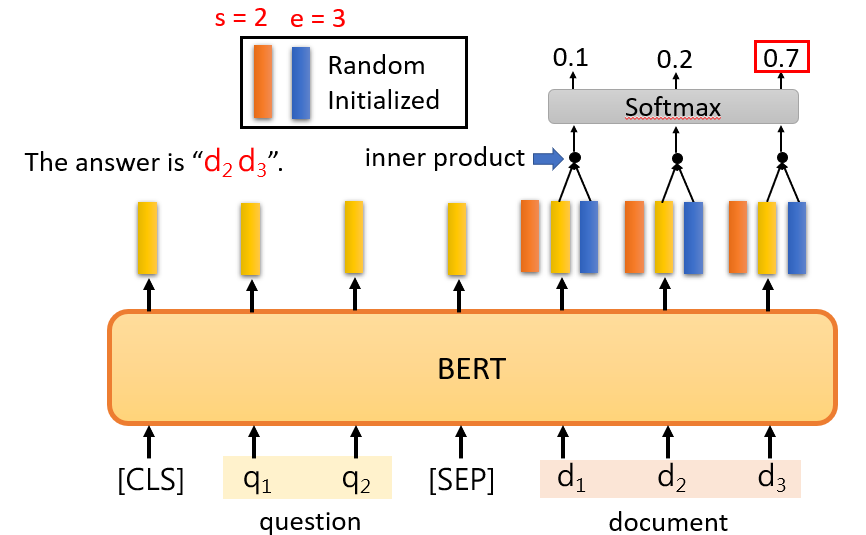
- Extraction-based Question Answering (QA)
Document: 𝐷={𝑑_1,𝑑_2,⋯,𝑑_𝑁 }
Query: 𝑄={𝑞_1,𝑞_2,⋯,𝑞_𝑀 }
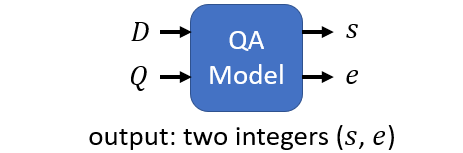
Answer: 𝐴={𝑑_𝑠, ⋯,𝑑_𝑒 }
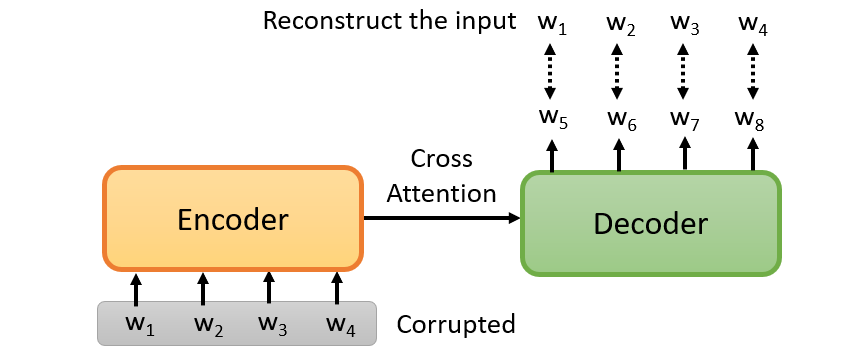
Downstream task
Label some data of the task we care.
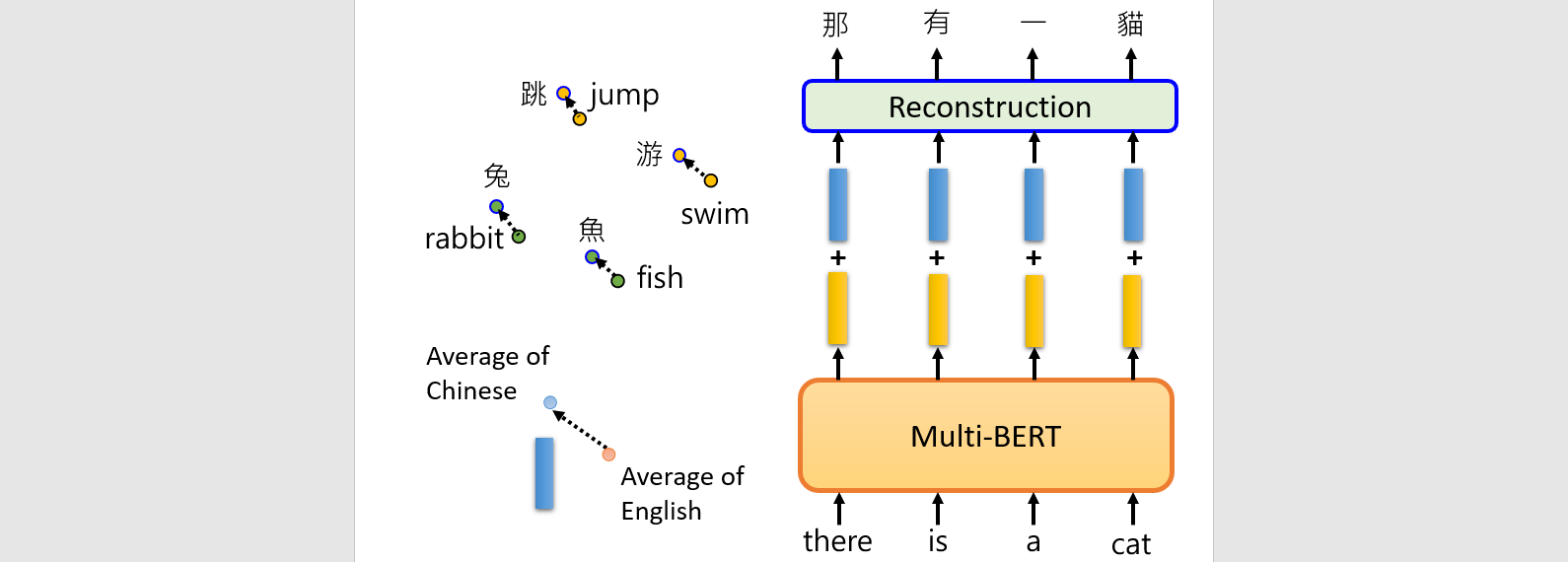
Multi-lingual BERT
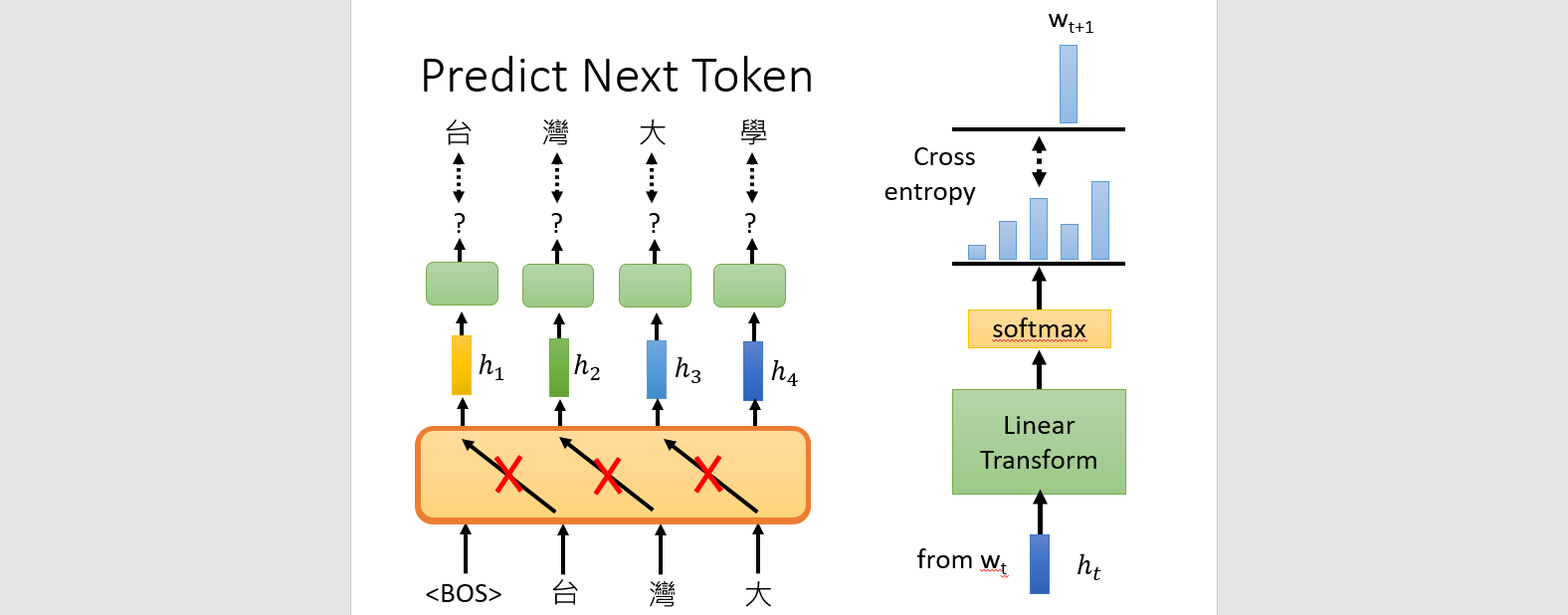
Generative Pre-trained Transformer (GPT)
Transformer decoder. Predict next token.
In-text learning
No gradient descent. (few shot, one shot, zero shot)
